Loading
Alright, let's dive into the world of machine learning by taking a dataset and training it with a machine-learning algorithm. As we progress, we will also learn the underlying theories. Keep in mind that to run an ML algorithm, you need to have familiarity with libraries such as NumPy, Pandas, Scikit Learn, etc., and a good understanding of the Python programming language. You can either follow along with the blog and learn about these libraries as you go, or you can familiarize yourself with them beforehand. I have also created a blog on Getting Started with ML that includes a list of resources in an order that I recommend.
To train a dataset into an ML model, you need data, right? But where will you find this data? One great platform to obtain such data is Kaggle. On this website, you can find a wide range of datasets covering different fields and industries. When starting out, a beginner-friendly dataset such as the House Price Prediction dataset can be a great choice. Kaggle is not just a repository of data but also a community where you can connect with other data scientists, participate in competitions, and share your projects.
To start working with machine learning, it's important to have a proper environment for writing and running your code. One simple solution for setting up such an environment is to use Google Colab. This is a free service offered by Google that enables you to write and execute your ML code. All of the necessary libraries required for running an ML model are already installed on Google Colab, making it an easy and convenient option. However, you can also choose to run everything on your local machine by installing the required libraries using pip or using a package management system like Anaconda, which provides all the necessary libraries in one package. Whether you use Google Colab or your local machine, you'll need to have the right tools and libraries in place to successfully run machine learning models.
Understanding the dataset is crucial for building an accurate and reliable machine-learning model. It helps in data quality, feature selection, data pre-processing, model selection, and evaluation. Without understanding the dataset, inconsistencies, irrelevant features, and inaccurate evaluations can lead to poor model performance.
For our example, we choose to use the house price prediction dataset from Kaggle. Here you can see the data is in CSV format which is the most common format for machine learning. The dataset includes various features, such as date, price, number of bedrooms, bathrooms, floors, and more. Our objective is to predict the house price using a supervised learning method, which involves training a model using relevant features. A feature is a characteristic of the data that is used to train the machine learning model to recognize patterns and make predictions. In our example, the relevant features are the number of bedrooms, bathrooms, floors, and other relevant information. The "Price" is the target variable, and all other variables are considered features.
To begin working with our dataset, we will import it using the "pandas" library and the "read_csv" method. This will allow us to easily load the data from the CSV file into our program. To avoid modifying the original data, we will make a copy of the dataset using the "DataFrame" method in pandas. This will allow us to perform any necessary data manipulations without affecting the original dataset.

As we can guess from the dataset that “date” is irrelevant in our dataset. So, We can eliminate the "Date" feature since it has no effect on predicting the house price.
Data preprocessing is an essential step in machine learning that involves various techniques such as removing irrelevant or duplicated data, handling missing values, correcting inconsistencies, data normalization, feature engineering, and data augmentation. However, the specific preprocessing steps required may vary depending on the nature of the data and the project's requirements. In this particular case, we are fortunate to have a relatively clean dataset, and to keep this blog simple, we will not perform all of the data preprocessing techniques mentioned.
Let's see what type of data we have in each column of our data to check the data types of our dataset columns.
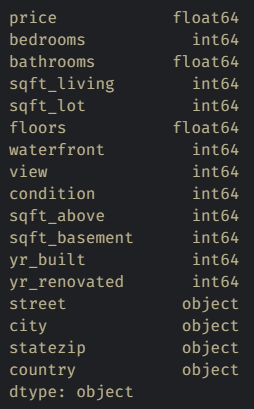
Here we can see street, city, state zip, and country are in object type, and the rest of the columns are in some form of numerical type, either int64 (integer number) or float64 (decimal number).
ML algorithms cannot work with categorical data (categorical data refers to data that represents specific categories or labels). In our dataset street, city, state zip, etc. are categorical data. Categorical data is important in machine learning because it can help to categorize and classify different types of data. However, machine learning algorithms often require numerical data, so categorical data needs to be converted into a numerical format through a process called feature encoding before it can be used in the training of a machine learning model. There are several techniques for feature encoding, such as one-hot encoding, label encoding, and binary encoding. One-hot encoding creates binary columns for each category, where a value of 1 indicates the presence of a category and 0 indicates its absence.

Label encoding assigns a numerical label to each category, and binary encoding represents each category as a binary string.

Proper feature encoding is crucial to ensure that the categorical data is represented in a meaningful way and that the machine learning algorithm can learn from it. Choosing the right encoding technique depends on the nature of the data and the requirements of the specific machine-learning model.
For our example let's separate all the categorical data and turn them into numerical data using Label Encoding.

In this code snippet, we are defining an array called "cat_cols" that contains the names of all the columns in the dataset that have the data type "object." We are using scikit-learn, which is a Python library for machine learning, to easily perform various machine learning tasks. We can use the LabelEncoder function from scikit-learn to convert our categorical values into numerical values. The LabelEncoder function maps the categorical values to numerical values, making it easier to work with the data. For instance, here you can see "Seattle" is mapped to the number 35. Overall, the LabelEncoder is a convenient tool for preprocessing categorical data in machine learning.

